
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- XAI
- PM4Py
- Digital Pathology
- Text generation
- multi modal
- Random Undersampling
- Generative modeling
- 국비지원교육
- Condensed neares neighbor rule
- 딥러닝
- 병리 AI
- GAN
- Fixed Learning
- 거리 기반 이상탐지
- Process Mining
- 밀도 기반 이상탐지
- Data Imbalance
- Sequence data
- Petri net
- Gausian Density Estimation
- Inatance segmentation
- SQL 데이터 분석 첫걸음
- auto encoder
- Meta heuristic
- One-Sided Selection
- Tomek links
- OCSVM
- Grad-CAM
- 프로세스 마이닝
- Clustering 기반 이상탐지
- Today
- Total
Create Opportunities
[병리 AI] Multi-pathology Detection and Lesion Localization in WCE Videos by Using the Instance Segmentation Approach 논문 리뷰 본문
[병리 AI] Multi-pathology Detection and Lesion Localization in WCE Videos by Using the Instance Segmentation Approach 논문 리뷰
kimjaeyoon 2022. 11. 7. 12:28Background
논문의 제목에서 알 수 있다시피 Instance segmenation 기반의 접근을 통해서 병리 이미지에 대한 Multi object detection과 그리고 병변 위치를 localization 할 수 있도록 해보자! 하는 그런 연구의 논문이다. 논문의 Method를 이해하기 전 알고 가면 좋을 내용이 있다. 우선, 본 논문은 자동 진단 시스템과 관련된 task를 다루는 논문이다. 자동 진단 시스템은 점점 더 발전하고 있고, 본 논문 이전에도 진단 자동화와 관련된 연구는 무척 많았기 때문에, 이전 연구들이 고안해낸 시스템들의 한계를 언급하면서 시작하고 있다.
1. 자동화된 시스템으로 진단을 하게 되면, 시스템이 보통은 이전에 진단을 내려본 경험이 있는 병들로만 진단을 내리게 된다. 이게 한계다. 그래서 새로운 병이 나타났을 때, 이것에 대해서 감지할 수 있는 기능이 보통은 없다.
2. 두번째로는 Multi-Object detection을 보통은 수행하지 못한다는 것이다. Pathology 이미지가 있을 때, 둘 이상의 병변 위치를 감지하는 것은 기존에는 쉽지 않았다고 언급하고 있다.
그래서 논문에서의 연구는 WCE라는 진단도구를 거쳐서 나오는 데이터들에 대해서 Instance segmentation 기법을 적용해서 Multi-Object detection 문제를 풀 수 있도록, 즉 둘 이상의 병변을 하나의 이미지에서 감지할 수 있도록 해보겠다! 라고 얘기하고 있다.

(WCE는 Wireless Capsule Endoscopy의 약자이다. 논문에서는 이를 위장관 시각화 능력에 혁명을 일으킨 진단 도구다. 라고 말하고 있다. 이 캡슐이 몸에 들어가는 내시경 역할을 한다고 보면되고, 기존 내시경 도구들은 십이지장 부분, 소장의 첫 번째 부분에만 도달하고, 또 대장 내시경도 대장의 전체를 탐지하는 데에는 제한이 되었다고 한다. 근데 WCE는 한 번 들어갔다 나오면, 5만개 이상의 이미지 데이터가 포함될 수 있을 정도로 아주 영향력있는 진단 도구라고 한다. 근데 이런 좋은 도구를 활용해도 아직까지의 기술력으로는 한 번에 하나의 병변만 탐지할 수 있다고 한다. 그래서 이걸 활용해서 더 좋은 무언가를 뽑아보자! 라고 얘기하고 있다.
Instance Segmentation !?
일단 Segmentation은 분할을 의미하고, 어떠한 object를 전체 이미지로부터 분리해낼 수 있는 기능을 한다. Semantic segmentation과 Instance Segmentation의 차이가 뭔지 생각해보면, 먼저 Semantic segmentation 여기 그림에서 Bottle이랑 cup이랑 cube 이것들을 object로 인지하지 않고, 그냥 서로 다른 class로 인식하고 판별하는 접근이라고 할 수 있다. 그래서 유사한 형태인 Cube들은 같은 class로 인식하게 되는 특징이 있다. 근데 Instance Segmentation은 좀 더 세밀하게, 일단 각각을 object로 인식하고 또 같은 형태의 object여도 구분을 지어줄 수 있는 특징을 가진다고 보면된다. 그래서 이미지가 있으면 여기에 존재하는 모든 객체를 탐지하는 동시에 각각의 경우를 정확하게 픽셀단위로 분류해서 진행하는 task라고 보면 된다.
어쨌든, 이런 Instance segmentation으로 논문에서는 병리 이미지 데이터에 대해서 하나가 아닌 둘 이상의 병변을 detection하는 접근을 보여주고자 합니다.
Prior Study
CNN기반의 기술들이 어떤 영향을 주었는지 얘기해주고 있고, 이 때는 데이터들은 MRI 장비로부터 대부분 얻어낼 수 있었다고 한다. MRI 데이터에 대해 CNN기반의 관련 기술이 물론 당연히, 진단 시스템에서 인상적인 성능을 보여줬다. 그리고 또 기존 학습된 모델을 활용하는 Transfer Learning 통해서 가지고 있는 적은 데이터셋에 대해서만 훈련하고 약간의 fine tuning을 통해서 자동 진단 성능을 더 높일 수 있음을 말하고 있다.
근데 이제 결국 중요한 점 어쨌든 multi object detection task를 수행하지 못했다는 것이다.
Prior Study - U-Net
Segmentation의 성능만 놓고 본다면, 기대해볼 수 있을만한 모듈이 바로 U-net이다. 일단 이렇게 U자 형태로 이미지의 크기가 줄어들었다가 다시 늘어나기 때문에 U-Net이라는 이름을 가지고, 두가지의 단계를 거치도록 architecture가 구성되어 있는데
1. 먼저 Input 이미지가 들어오면, CNN의 일반적인 convolution과 pooling 연산이 진행됩니다. 채널의 수를 늘리고 너비와 높이를 줄이는 것이라고 볼 수 있고, 이 단계를 contracting path라고 하고,
2. 그리고 다음으로는 이 압축된 이미지를 다시 up convolution연산을 통해서 expanding한다. 그리고 이 expanding 하는 단계에서는 이전에 contracting path에서 이미지 사이즈가 변화될 때 각각의 픽셀 정보들을 또 같이 활용할 수 있게 한다. 그래서 확장하는 단계에서는 기존 이미지의 특징을 잘 보존할 수 있다는 특징을 가진다. 최종적으로는 어쨌든 이러한 U-Net의 구조가 Semantic segmentation에서는 상당히 좋은 성능을 보이는 대표적인 CNN 기반의 모델이었다.. 라고 언급해주고 있다.
근데 이제 결국 중요한 점 어쨌든 multi object detection task를 수행하지 못했다는 것이다. ㅋㅋ... 어쨌든...
Base Module
Mask RCNN과 PANet을 얘기하고 있다. 논문에서 되게 다양한 모듈들을 언급하기 때문에, 깊지 않게 그냥 보고만 넘어가도 될 것 같은데, 이들은 Instance segmentation을 위한 가장 기본 baseline이 되는 모듈이라고 보면 되고, 얘네가 가지는 subnet 부분을 개선해서 본 논문의 method를 제안하고 있다고 보면 된다.. 근데 사실 되게 복잡한게, 이 Mask-RCNN이라는 모듈도 굉장히 많은 단계를 거치고 거쳐서 등장한 훌륭한 모델이다. 아 알아야 할 것들이 너무나 많다.

일단, RCNN은 어떠한 이미지가 들어왔을 때, 이 이미지에 대해서 우선적으로 Selective search 단계를 진행한다. 이건 이제 object가 존재 할만한 위치 2000개 정도를 찾게 되는 단계입니다. 그리고 2000개의 이미지를 개별적으로 CNN 네트워크에 넣어서 Feature vector를 얻게 됩니다. 그리고 이 feature vector를 가지고 SVM으로 classification task를 수행하고 regressor를 이용해서 정확히 물체의 위치가 어디인지 그러한 bounding box가 어딘지 좀 더 정확하게 조절한다고 한다. 이 기본적인 RCNN 이후에도 Fast RCNN, Faster RCNN같은 더 빠른 속도로 학습이 가능한 모듈들이 등장했다.
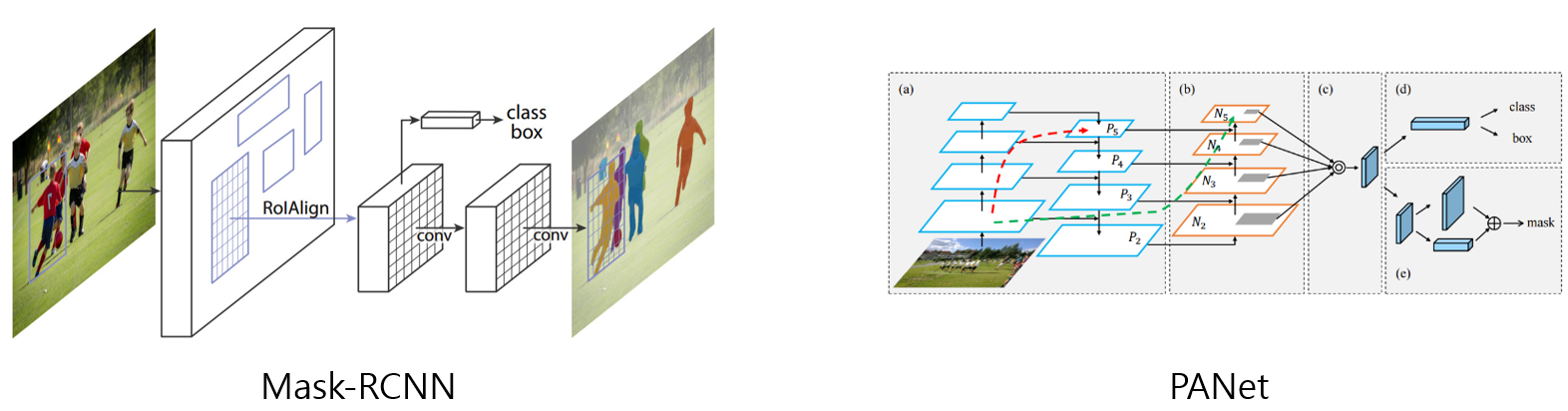
근데 지금 이 논문에서 Introduction에서 언급하는 Baseline이 된다고 하는 모듈은 Mask-RCNN입니다. Mask RCNN은 Faster RCNN에서 Feature를 추출하는 방식을 더욱 개선하고, segmentation task를 추가시킨 방식이다. 그래서 1차적으로 class에 따른 Mask를 예측할 때, 여러 가지 task를 한 model로 학습하여 object detection의 성능을 높인 모델이라고 얘기해주고 있다.
그리고 또 PANet이라는 모듈도 Introduction에서 언급하고 있는데, 이 PANet은 Mask RCNN을 기반으로 하고 마찬가지로 Instance segmentation을 위한 모듈이다. 이것도 Mask RCNN에서 새로운 기법들을 조금은 복잡하게 병합해서 Instance segmentation의 성능을 올리기 위해 등장한 모듈이라고 보면 된다.
Framework
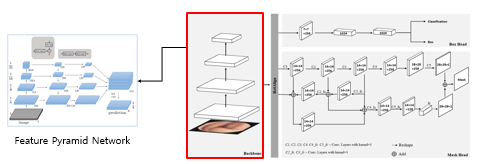
Framework에서 가장 중요한 점은 MS-RCNN이나 Bmask-RCNN 처럼 기존 모듈에다가 새로운 뭔가를 병합해서 성능을 높이는 방향이 아니라, 기존 PANet 아키텍쳐의 핵심이 되는 부분에 집중해서 그 부분을 개선하는 것에 초점을 맞췄다는 것이다. Instance segmentation task을 위한 이전 모듈들과 비슷하게 backbone 구조는 이렇게 피라미드 네트워크로 구성되어 있다.
이후 RoIAlign 단계를 설명하자면, 일단 RoI는 Region of Interest이고, 이미지 내에서 관심있는 영역을 의미한다.
어쨌든 이 RoIAlign을 사용하는 것에 대한 의의도 논문에서는 강조하면서 언급하고 있는데, 사실 RoIAlign 기법은 MaskRCNN에서도 사용된 기법이다. 원래는 Object detection을 위한 모델들이 전부 RoIPool 기법을 사용했었는데, 논문에서는 RoIAlign을 사용함으로써 얻게 되는 이점을 언급하고 있습니다.
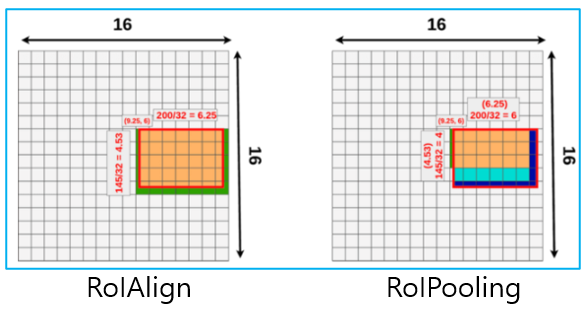
단지 Object detection만을 위한 모델들은 Object들의 완전 정확한 위치정보를 담는 것이 별로 중요하지 않았다. Feature map에서 object를 탐지하고, max pooling으로 영역의 범위를 반올림해서 적당히 탐지가 될 정도로만 pooling을 하면 됐는데, 이게 영역을 나누는 데 있어서는 큰 문제가 되지 않지만, Instance Segmenation처럼 픽셀 하나하나 세세히 detection 하는 경우 문제가 생길 수 있다. 그래서 인스턴스 세그멘테이션을 위해서는 RoIPooling이 아닌, RoIAlign을 사용해야지 여러 개의 object를 segmentation할 수 있다고 한다. 이중선형 보간법을 사용한다는데, 나도 모르겠다. 그림에서의 결과만 봐보면, 일단 주황색 영역이 보존되는 데이터의 특성 영역을 의미하는데 RoIAlign을 사용하였을 때, 훨씬 더 많은 특성이 보존된다는 것을 말해주고 있다.
논문에서는 이 Mask Head 부분을 개선해야한다고 말하고 있지만, 이 부분에 대한 설명이 솔직히 거의 없다. Method 부분에서 인용 논문의 Method를 참고하라는 식의 정말 성의 없는 논문이다. 일단 그래도 아키텍쳐를 보았을 때는 backbone에서 가져온 Feature Pyramid map의 마지막 층에서 뽑아낸 Image를 인풋으로 활용하게 되는 것 같고, 그것을 "똑같은" convolution layer에 적용을 시킨다. 이렇게 반복적으로 같은 convolution 연산을 해주는 이유는 그냥 여러 번 수행해서 얻게되는 feature들이 조금씩 다른 특징을 가질텐데, 그냥 그렇게 뽑아낸 feature들을 좀 많이 활용해보자.. 하는 것 같다. 어쨌든 논문에서는 이런식으로 여러 번 같은 convolution 연산을 해서 이것들을 조합해서 성능을 높일 수 있을 법한 structure를 보여주고 있다.. 논문도 설명해주지 않아서 자세한 설명을 못하겠다.
그리고 trainin을 어떻게 시켰는지에 대해서 말해주고 있는데, Stochastic gradient descent를 base로 하는 Optimizer를 이것 저것 사용해보면서 training 과정을 발전시켰다고 말해주고 있다. 최종적으로는 NAG라는 생소한 Optimizer 사용해서 training 시켰다고 하고, 이 최적화 방식은 다음 업데이트 해야할 가중치를 속도에 따라서 조절하는 방식이라고 한다.
그리고 또 고차 모멘텀을 사용했을 때 수렴속도를 개선한 부분을 강조하고 있고, 이후에 실험에서도 고차 모멘텀을 사용했을 때 실험 결과가 어떻게 달라졌는지를 말해준다.
Experiments
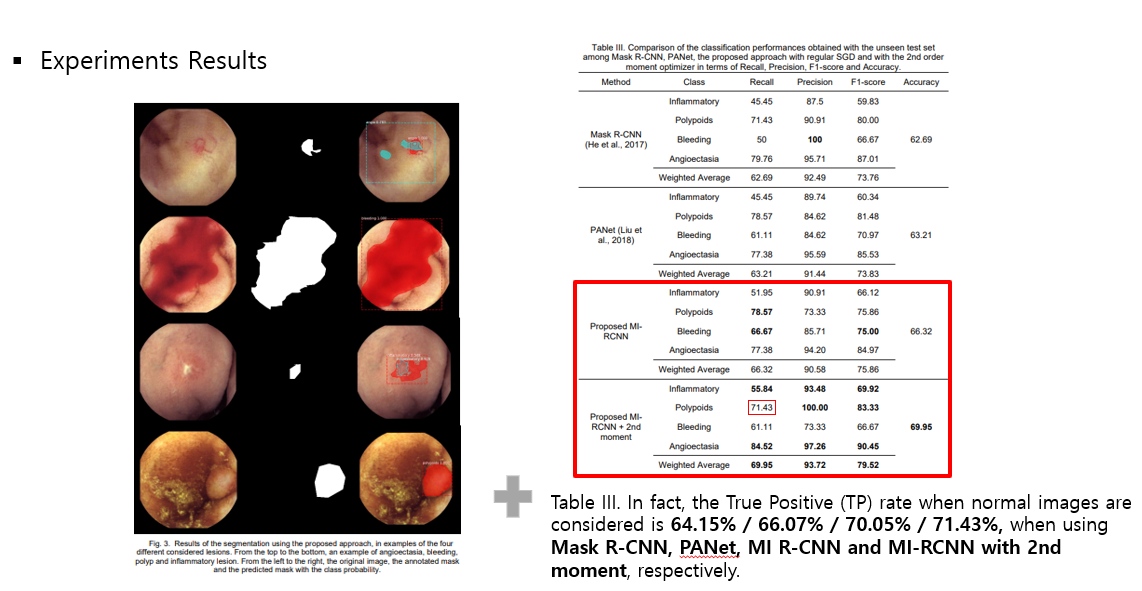
이미지들은 MI-RCNN을 사용해서 segmentation한 결과를 보여준다. 혈관확장증, 출혈, 폴립, 염증성 병변,, 이렇게 네가지가 전부 다른 병변의 예시이다. 결과를 봐보면, 지금 첫 번째와 세 번째 예시에서 하나 이상의 병변이 확률값으로 발견되고 있다. 이러한 경우에 더 높은 확률로 결과가 반환된다고 보면 된다.
- 결과 테이블을 봐보면, MI-RCNN이 inflammatory polypoids angioectasia 에서 특히나 좋은 성능을 보였고, 출혈을 감지하는 데 있어서는 좀 많이 별로인 성능이 나왔다. 출혈 증상의 이미지를 봐보면, segmentation을 할 때 그림자 부분과 좀 흐릿한 부분들을 헷갈릴 수밖에 없음을 예상할 수 있는 것 같는 것 같다."출혈"의 이미지라는 특징 상 그라데이션처럼 나타나니깐.
- 폴립에서의 detection은 MI-RCNN을 적용했을 때 항상 최상의 결과를 얻었지만, 2nd momentum을 사용한 경우에는 이상하게도 Recall이 낮게 나온 것을 확인할 수 있다. 그에 대한 이유는 딱히 언급하지 않았고, 그냥 전체적으로 봤을때 2차 momentum 사용했을 때 더 좋은 성능을 보이니깐, 괜찮다. 라고 얘기해주고 있다.
- 마지막으로 inflammatory(염증성 병변)을 보면 precision과 recall값 사이에 상당한 차이가 발생하긴 하지만, MI-RCNN에서 그래도 최고 성능을 보였다고 얘기해주고 있다.
+ 그리고 또 추가적으로 이제 의사들의 정성적인 평가와 비교했을 때 모델의 성능이 어떠했는지도 논문에서는 언급하고 있습니다. WCE이미지를 가지고 진단해본 경험이 좀 많은 의사와 경험이 적은 의사 선생님들을 골고루 실험에 참여하게 하였고, 병변이 포함된 이미지를 가지고 진단을 내려보라고 하였을 때, 평균적으로 병변의 절반도 발견해내지 못했다고 한다. 그에 반면, MI-RCNN이 동일한 병변 이미지에 대해서 어느정도로 detection을 잘 했는지를 수치적으로 얘기해주고 있다.
+ 그리고 또 정상 이미지를 잘 분류했는지는 논문에서 초점을 두고 있는 부분이 아니어서 관련된 결과를 표에 제시하지 않았는데, 그래도 짧게 True Positive 비율을 수치적으로 말해주고 있고, 어느정도 잘 맞춘 것을 확인할 수 있다.
아... 논문이 너무 난해하다. 정리된게 없고, 제안하는 Method도 명확하지 않다.



