
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Grad-CAM
- Meta heuristic
- Text generation
- 거리 기반 이상탐지
- auto encoder
- Process Mining
- PM4Py
- Sequence data
- One-Sided Selection
- Data Imbalance
- Digital Pathology
- Generative modeling
- Petri net
- OCSVM
- Tomek links
- XAI
- Fixed Learning
- multi modal
- Gausian Density Estimation
- 국비지원교육
- Condensed neares neighbor rule
- 병리 AI
- GAN
- 프로세스 마이닝
- Random Undersampling
- Inatance segmentation
- Clustering 기반 이상탐지
- 딥러닝
- 밀도 기반 이상탐지
- SQL 데이터 분석 첫걸음
- Today
- Total
Create Opportunities
[데이터 애널리틱스] RNN(1) 본문

RNN을 배운다.
Snapshots을 통해 Hidden state를 추출하고 변환하는 기본적인 신경망은 Dynamic beviors의 특징을 학습하기는 어렵다.
Sequence data에 ANN, CNN을 동일하게 적용한다면, 데이터의 특성을 보존하여 학습하기엔 무리가 있다는 소리다.
아얘 불가한 것은 아니고, sliding predictor를 활용하여 CNN으로도 학습할 수 있긴 하다.

이상적으로 위와같이 Infinite-response model을 구축할 수 있으면 좋겠다만, 현실적으로 구현이 불가하다.
위와 같은 Sequence data의 Recursive한 특징을 이용하여 Yt=f(Xr, Yt-1) 로 접근을 해볼 수 있다.
그래서 아래의 그림이 기본 구조이다.
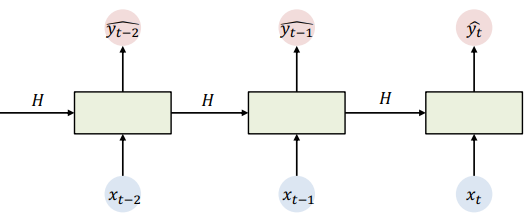
그래서 두 가지를 학습해야 한다.

1. Recurrence-Hidden state > t-1 시점의 정보를 바탕으로 t 시점의 정보를 도출
2. Input-Hidden state > 일반적인 ANN과 동일
다양하게 모델링 할 수 있다.

Backpropagation Through Time

W의 경우에는 이전의 Hidden state와의 관계를 같이 고려를 해줘야함을 알 수 있다.
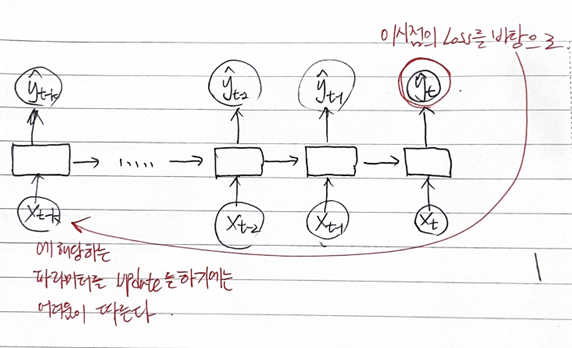
따라서, Gradient Vanishing problem은 불가피하다.
해결을 해야한다... 어떻게 ?
1. Activation Function (Ex. ReLU)
2. Parameter Initialization (Ex. Identity Matrix 활용)
3. Gated Units (Ex. LSTM, GRU...)
LSTM
정보에 대한 흐름을 컨트롤하는 Computational blocks에 기반
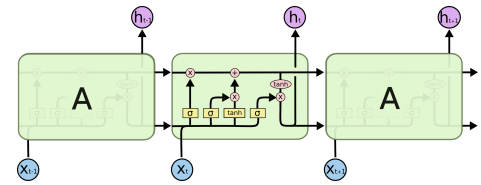
Memory cell state를 기본적으로 가지며,
Tree sigmoid gates를 활용한다.
1. Forget gate
2. Input gate
3. Output gate
일단 Basic RNN을 생각해보자.
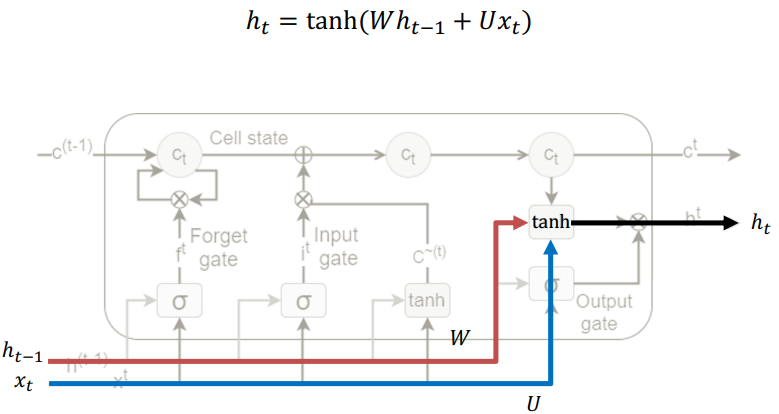
t-1시점의 hidden state와 t시점의 input 데이터를 바탕으로 tanh 활성화 함수에 태워서 t시점의 hidden state를 도출한다.
LSTM은 Cell state를 기반으로 하며, Linear한 Interaction을 바탕으로 값들이 업데이트된다.
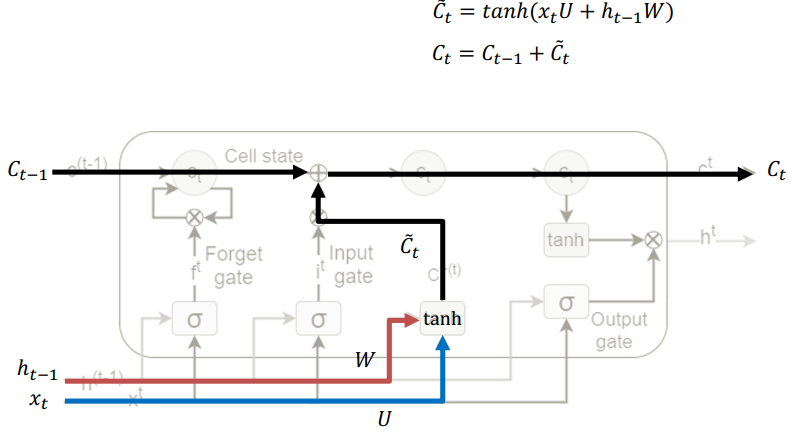
우선적으로 C^를 먼저 동일한 방법으로 구하고, 이를 t-1시점의 C와 Element wise sum 연산으로 t 시점의 C를 구한다.
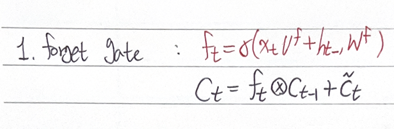
1. forget gate 작동
: 지금까지 저장되어 온 t-1시점의 C를 그대로 쓸 것인가, 버릴 것인가 결정
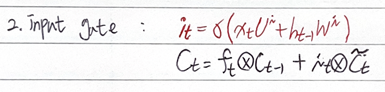
2. input gate 작동
: 현재 상태에서 구할 수 있는 정보들을 '얼만큼' 사용할지 결정

3.output gate 작동
: forget, input gate를 지나서 t시점의 C가 나올텐데, 이에 대해서 tanh 태운 뒤 output gate 적용 > 결과값을 완전 통과시킬지, 일부 차단할지 결정
위와 같은 방식으로 학습을 하면서 weight도 자연스럽게 학습되고, gradient vanishing 문제도 해결할 수 있다.
'데이터 애널리틱스' 카테고리의 다른 글
| [데이터 애널리틱스] Transfer Learning ? (0) | 2022.12.01 |
|---|---|
| [데이터 애널리틱스] RNN(2) (0) | 2022.11.30 |
| [데이터 애널리틱스] Data analysis with Process Mining (0) | 2022.11.18 |
| [데이터 애널리틱스] Event Logs (1) | 2022.10.03 |
| [데이터 애널리틱스] 프로세스 마이닝이란 ? (2) (0) | 2022.10.03 |



