
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- GAN
- Data Imbalance
- PM4Py
- Meta heuristic
- multi modal
- Grad-CAM
- 국비지원교육
- SQL 데이터 분석 첫걸음
- 프로세스 마이닝
- Tomek links
- 병리 AI
- Process Mining
- OCSVM
- Inatance segmentation
- Condensed neares neighbor rule
- auto encoder
- Random Undersampling
- XAI
- One-Sided Selection
- 밀도 기반 이상탐지
- Text generation
- Clustering 기반 이상탐지
- 거리 기반 이상탐지
- Digital Pathology
- Fixed Learning
- Petri net
- Generative modeling
- Gausian Density Estimation
- 딥러닝
- Sequence data
Archives
- Today
- Total
Create Opportunities
[데이터 애널리틱스] RNN(2) 본문
Basic RNN Implementation
광운대학교 조민수 교수님의 데이터 애널리틱스 교과목 자료를 참고합니다.
Pytorch → RNN 구현의 핵심적인 부분을 쉽게 정리한 내용입니다.
아래의 코드는 간단한 Text generation 과정의 주요 부분입니다.
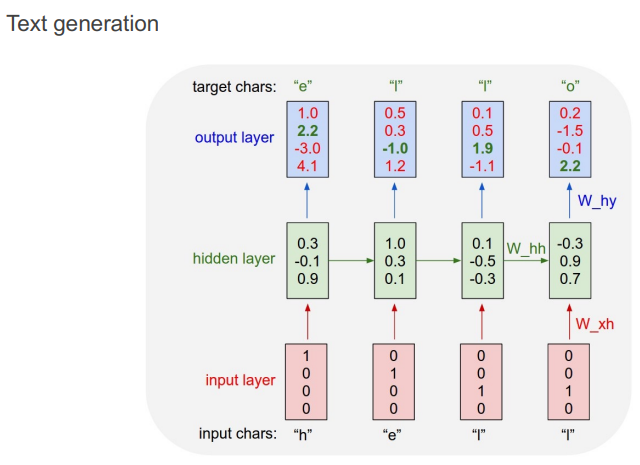
Encoding 함수 정의
# encoding 함수 정의
def string_to_onehot(string):
start = np.zeros(shape = n_letters, dtype = int) # 시작 벡터와
end = np.zeros(shape = n_letters, dtype = int) # 마지막 벡터
start[-2] = 1 # 시작 벡터는 [0, 0, ... ,1, 0]
end[-1] = 1 # 마지막 벡터는 [0, 0, ... ,0, 1]
for i in string: # 문자열 각각의 문자에 대한 Encoding 진행
idx = char_list.index(i) # idx : 해당되는 문자가 char_list의 몇 번째에 해당되는지
zero = np.zeros(shape = n_letters, dtype = int) # 일단 전부 0으로
zero[idx] = 1 # 해당되는 문자 위치를 1로
start = np.vstack([start, zero]) # start 아래로 Encoding된 문자 하나씩 쌓음
output = np.vstack([start, end]) # end
return outputDecoding 함수 정의
# decoding 정의
def onehot_to_string(onehot):
onehot_value = torch.Tensor.numpy(onehot) # Tensor to Numpy
return char_list[onehot_value.argmax()] # 문자로 반환
기본적인 RNN 구조
# Basc RNN
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# Layer 아래와 같이 정의
self.input2hidden = nn.Linear(input_size, hidden_size) # input_size -> 35
self.hidden2hidden = nn.Linear(hidden_size, hidden_size) # 35 -> 35
self.hidden2output = nn.Linear(hidden_size, output_size) # 35 -> 30(n_letters)
self.act_fn = nn.Tanh() # 활성화 함수는 Tanh 사용
def forward(self, input, hidden):
# input ~ hidden과 t-1시점의 hidden ~ t시점의 hidden
hidden = self.act_fn(self.input2hidden(input) + self.hidden2hidden(hidden)) # Hidden state는 두 가지를 학습
output = self.hidden2output(hidden) # hidden to output
return output, hidden
def init_hidden(self): # hidden vector에 대한 초기화
return torch.zeros(1, self.hidden_size)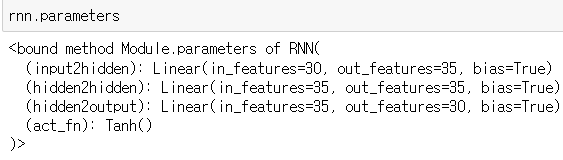
아래의 코드는 원하는 string을 인코딩한 뒤,
epoch만큼 학습을 진행하는 과정이다.
# Encoding (size : [35, 30]) / len(string) + start, end = 35
one_hot = torch.from_numpy(string_to_onehot(string)).type_as(torch.FloatTensor())
for i in range(EPOCHS): # epcoh = 100
# 초기화
optimizer_rnn.zero_grad()
hidden = rnn.init_hidden()
total_loss = 0
for j in range(one_hot.size()[0]-1): # 35번 반복
input_ = one_hot[j:j+1, :].to(device) # j번째 문자의 one hot / 2차원으로 [1, 30]
target = one_hot[j+1].to(device) # 1차원으로 [30]
output, hidden = rnn.forward(input_, hidden) # intput, hidden -> output, hidden
loss = loss_func(output.view(-1), target.view(-1)) # 예측 output과 target 간 loss
total_loss += loss
total_loss.backward() # backpropagation
optimizer_rnn.step() # optimizing
if i % 50 == 0:
print(total_loss) # loss는 ?
Inferencing
# start token 정의
start_tkn = torch.zeros(1, n_letters) # [1, 30]
start_tkn[:, -2] = 1 # 뒤에서 두 번째 1로 정의
with torch.no_grad(): # do not calculate gradient
hidden = rnn.init_hidden() # hidden 초기화
input_ = start_tkn.to(device) # input으로 start_tkn
output_string = "" # 뭐가 나올까
# generation
for i in range(len(string)):
output, hidden = rnn.forward(input_, hidden) # forwarding
output_string += onehot_to_string(output.data) # output 문자로 decoding
input_ = output # output문자를 다시 input 문자로
print(output_string) # 최종 generation"hello pytorch and data analytics." 에 대한 Generation 결과 ↓↓↓
hello pytorch ant datalatacandyti
작성중
'데이터 애널리틱스' 카테고리의 다른 글
| [데이터 애널리틱스] Auto Encoder (1) | 2022.12.01 |
|---|---|
| [데이터 애널리틱스] Transfer Learning ? (0) | 2022.12.01 |
| [데이터 애널리틱스] RNN(1) (0) | 2022.11.30 |
| [데이터 애널리틱스] Data analysis with Process Mining (0) | 2022.11.18 |
| [데이터 애널리틱스] Event Logs (1) | 2022.10.03 |
'데이터 애널리틱스' Related Articles
more



